![]()
di Carmelo Nucera
![]()
di Carmelo Nucera
IP su ATM - LAYER 3 SWITCHING
ATM è una tecnologia matura, scalabile ed inoltre molte manifatturiere hanno sviluppato e continuano a sviluppare prodotti di switching molto efficienti.
Daltronde anche IP si è rivelata una tecnologia robusta e scalabile, inoltre le recenti prove che IP ha dato nel supporto per la multimedialità hanno dato ulteriore prova della bontà di IP; questo senza tenere conto che la base di installato di IP è enorme e che nell'immediato futuro non si potrà fare a meno di venire incontro all'esigenza di "compatibilità all'indietro" con i sistemi installati.
ATM ha la capacità di fornire QoS control ma ciò con il costo di richiedere una filosofia connection oriented.
Da notare che il 90% della segnalazione in reti connection oriented, come ATM, è da imputarsi alla segnalazione di errori; ma questo software è di solito non completamente validabile e testabile quindi rischi di malfunzionamenti sono all'ordine del giorno. Al contrario, la segnalazione in IP è minima essendo la rete connectionless e questo va a vantaggio dell'affidabilità del protocollo in quanto è molto piccolo.
Però non si può non notare che la tecnologia ATM di fast cell switching abbia raggiunto potenzialità incredibili.
Si vorrebbe questa velocità per venire incontro ai problemi dovuti, nelle reti tradizionali, sia alla lentezza dei router che al loro costo (più un router è veloce e più il suo prezzo per porta è elevato).
I protocolli sinora sviluppati per sfruttare IP su ATM (RFC 1577,LANE,NHRP,MPOA) hanno tutti in comune la visione di non tenere conto della reale topologia della rete bensì considera la rete ATM come una "nuvola" generica su cui si può fare una connessione virtuale end to end tra gli host interessati (NB virtuale). Questo crea problemi quali ad esempio la duplicazione di compiti tra IP ed ATM, inoltre così tutti gli host sono virtualmente collegabili tutti direttamente tra loro facendo esplodere la dimensione delle tabelle che conservano informazioni sulle Virtual Connection.
Molti sono stati gli sforzi delle manifatturiere tesi aprodurre nuove tecniche di switching che non nascondessero la reale topologia della rete ma fossero basate sulla sua reale forma.
Propriamente non si può parlare più di reti ATM in quanto non si usano più parti software proprie di ATM, come la segnalazione P-NNI per l'instaurazione di un VC, ma si usano solo le parti hardware di una rete ATM e cioè i fast packet switch.
Di seguito forniamo una descrizione di massima di due tecniche ad oggi molto in voga ma, pur essendo stati prodotti dei draft in IETF, non sono state ancora standardizzate in quanto trattasi di soluzione proprietarie di cui non è certa l'interoperabilità con soluzioni di altre manifatturiere e, come nel caso della CISCO, orientate di solito alla soluzione di particolari problemi di interconnessione e non sufficientemente generiche. Daltronde, a tutt'oggi, la classica ATM che doveva essere scalabile dalla LAN sino alla WAN mondiale deve ancora dimostrare questa qualità e le soluzioni orientate al problema sono ancora le più utilizzate.
IP SWITCHING
Il concetto di flusso è emerso in studi degli anni recenti riguardo IP. Un flusso è un insieme di pacchetti mandato da una particolare sorgente verso un particolare destinatario, i quali sono relazionati in termini di routing e di politica di gestione che possono richiedere (es una certa QoS). Il concetto di "flusso" in una rete connectionless è equivalente al concetto di "connessione" di una rete connection oriented ovvero entrambi sono il soggetto base riguardo lo scambio di dati in un dominio continuo piuttosto che per scambi sporadici (es. Videotelefonia piuttosto che interrogazione di un DNS).
Il concetto di "pesantezza" che vi è nello stabilire una connessione è stato ribadito più volte ma è anche vero che la connessione è la base per garantire la QoS. La filosofia dell'IP switching tende a mantenere uno stato della rete (che si concretizza nello stato degli switch) "soft" piuttosto che la versione "hard" di stato, cioè un vero concetto di connessione all'interno dello switch. La differenza risede in come il software dello switch vede i flussi che gli arrivano.
Il concetto è che uno stato soft impatta le prestazioni della rete ma non è cruciale rispetto alla filosofia di lavoro della rete stessa. Quindi il mantenere un soft state può essere di ausilio ad esempio per un QoS routing ma non viene strravolto il concetto ri routing IP hop-by-hop, al contrario di ATM classico che, instaurando la connessione virtuale, è come se avvicinasse gli host evitando il routing di livello 3. In effetti il routing viene eliminato in quanto l'informazione di instradamento è distribuita su tutta la rete di switch.
Funzionamento di IP Switching
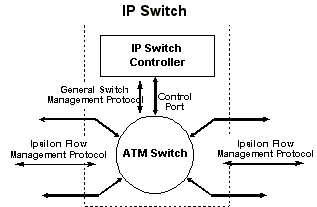
Lo schema di un IP switch è il seguente
E' costituito dall'hardware di un normale switch ATM ma con la logica di controllo definita nello IP Switch controller.
Vengono scambiate informazioni mediante due tipi di protocolli:
General Switch Management Protocol (GSMP): è il protocollo con cui il controller comunica con lo switch, è ciò che sostituisce (in tutto) il software ATM. E' questo protocollo che prende le decisioni in base ai dati che gli vengono forniti sul tipo di flusso che deve essere smistato; crea cioè un mapping in memoria che identifica i flussi e di conseguenza ordina la commutazione su di una particolare porta allo switch ATM.
Ipsilon Flow Management Protocol (IFMP): è un protocollo che serve per scambiare le informazioni sul flusso tra gli IP switch, ad esempio la QoS richiesta da un particolare flusso (tra l'altro esiste un informational RFC su questo ovvero un documento informativo che IETF ha recepito ma su cui non vi è stata standardizzazione nè endorsement).
Allo startup del sistema vengono stabiliti dei VC tra un IP switch e gli adiacenti usando dei well-konw VPI/VCI.
Un flusso IP viene caratterizzato in base ai campi degli header IP/TCP/UDP nei quali vengono specificati ad esempio IP source, IP destination ma anche QoS richiesta (tendenzialmente la QoS si specifica a livello trasporto). Quando il primo pacchetto di un flusso IP arriva al IP switch (su di un VC di default) viene classificato in base a politiche di instradamento eminentemente locali. Una volta fatto questo, lo switch controller istruisce l'ATM switch per far sì che commuti sempre, d'ora innanzi, i pacchettidi quel flusso su di un particolare VPI/VCI in uscita.
Ma tutto questo non sarebbe funzionale, per esempio a garantire il QoS, se gli switch non si informassero di continuo tramite IFMP. Ripetiamo che, al momento della classificazione del flusso, lo IP switch controller che è connesso allo IP switch mediante un VCI x' sulla porta c, decide di commutare il traffico ricevuto in ingresso da un VCI x su di una porta di uscita di default e contemporaneamente invia allo switch che lo precede la richiesta di inviare, d'ora in poi, tutti i pacchetti di quel flusso sul VCI x e porta i. La richiesta è incapsulata in un IFMP (come fosse un ICMP redirect). Lo switch che segue quello in questione, classificherà il flusso a sua volta ed invierà a sua volta una richiesta di commutare sull'uscita VCI y e potrta j. Per cui, dopo un transitorio in cui gli switch informano i "precedenti" nella catena di instradamento, la situazione per uno switch è come da figura in cui ad un particolare flusso corrisponde un particolare mapping ingresso/uscita di VCI e di porte.
Così in breve si instaura, anzichè una connessione, una serie di stati soft ognuno locale al singolo switch. Il vantaggio della tecnica risiede proprio nella località delle scelte nonchè nella robustezza dovuta all'assenza di connessione.
I problemi sono essenzialmente nella possibilità di scalare questa tecnica su ambiti geografici poichè se il numero di flussi da commutare cresce l'IP switch controller deve divenire sempre più intelligente e capace come memoria. Inoltre ci sono diffidenze sulla possibile interoperabilità di questa (ma in generale anche di altre tecniche di layer 3 switching) con soluzioni di altri prooduttori. Infine la capacità di caratterizzare i flussi non sembra a tutt'oggi capace di eguagliare le prestazioni di QoS che ATM garantisce. Ma questi problemi sono strutturali con una tecnologia nuova e solamente il tempo ci dirà se questa idea sarà vincente (in fondo nessuno avrebbe scommesso 20 anni fà sulla longevità del TCP/IP).
TAG SWITCHING
La crescita esplosiva di Internet ha creato un serio problema agli Internet Service Provider (ISP) ed alle loro reti. Cisco ha presentato una nuova tecnica denominata Tag switching che è orientata alla ottimizzazione del routing in una rete omogeneamente costituita ad esempio da hardware ATM.
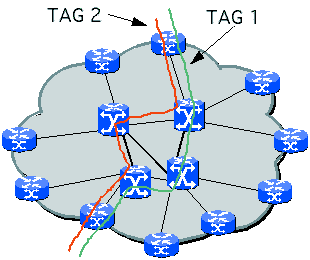
E' basata sul concetto di "label swapping" ovvero il pacchetto (o la cella) della rete è preceduta da una label di lunghezza fissa in base alla quale si effettua l'instradamento.
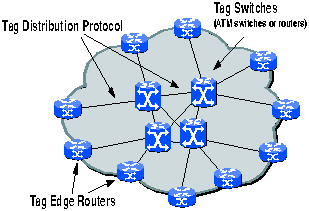
Una rete Tag switched è costituita da tre componenti:
Tag edge router (TER): localizzati sul bordo della rete, essi operano le cosidette funzioni a valore aggiunto (ad esempio stabiliscono la QoS che il flusso di dati dovrà avere) nonchè applicano i "tag" ai pacchetti
Tag switch (TS): smistano i pacchetti, all'interno della rete, in base ai tag dei pacchetti stessi.
Tag distribuition protocol (TDP): in congiunzione con normali tecniche di routing del livello di rete (es. OSPF per IP), TDP è usato per trasmettere informazioni dei tag, tra gli elementi della rete precedentemente definiti.
La sequenza di operazioni per il forwarding di pacchetti in una rete tag switched è la seguente:
- TER e TS usano algoritmi di routing standard (es. OSPF) per determinare il percorso dei pacchetti nella rete. L'uso di algoritmi standard conferisce interoperabilità con dispositivi non-tag switched operanti al di fuori della rete "tagged".
- Le informazioni raccolte al punto precedente servono al TDP per generare e distribuire i vari tag ad ogni TS o TER.
- Quando un TER riceve un pacchetto dall'esterno, analizza l'header IP, esegue calcoli in base ad esempio alla QoS ed applica un tag al pacchetto (ponendoglielo in testa) che qualifica lo stesso . Successivamente invia il pacchetto al prossimo TS, come derivato dal primo punto.
- Il TS non legge l'header IP ma smista il pacchetto solo in base al tag.
- Quando il pacchetto raggiunge il TER alla estremità opposta il tag viene tolto ed il pacchetto consegnato.
Abbiamo mensionato i compiti delle componenti ed adesso scendiamo in dettaglio nella descrizione di esse.
Tag Edge Router
Sono dei veri e propri router di livello 3, che attaccano i tag ai pacchetti, li tolgono ed eseguono classiche funzioni di livello 3, es. Firewallig ed QoS classification.
Il modo in cui si producono i tag è vario e lasciato intenzionalmente flessibile. Un modo è usare le normali procedure di routing per mappare l'indirizzo IP di destinazione con un particolare tag, uguale per ogni indirizzo IP da cui proviene purchè vada allo stesso TER di uscita. Ma si può anche tenere conto da quale indirizzo IP un pacchetto proviene, oppure dalla QoS richiesta per mappare, su tag differenti e quindi su percorsi differenti, pacchetti destinati allo stesso TER di uscita.
Tag Switch
Sono il cuore della rete. Un TS è generalmente un fast packet switch che usa tecnologie ATM, in cui il tag è associato con l'header di livello 2 (es. il tag è scritto al posto del VCI/VPI field). C'è un software proprietario che non instaura la connessione bensì smista solo i pacchetti sullo switch ATM in maniera connectionless (in base alla tabella che associa ad una porta di ingresso una porta di uscita). Si possono però usare anche tecnologie non-ATM, ad esempio SMDS, sebbene gli switch ATM siano di gran lunga l'hardware più evoluto nel campo dello switching.
Tag Distribuition Protocol
E' il protocollo di scambio dati tra TER e TS. I TER costruiscono le tabelle di routing con i normali protocolli di routing IP (es.OSPF) ma distribuiscono le informazioni ai TS e TER vicini con il TDP per aggiornare i Tag Information Database TIB dei TER e TS. Senza dilungarci sul TDP, di cui peraltro la implementazione è ancora propietaria Cisco, il concetto è distribuire i tag in modo che, dopo la scoperta che un flusso, ovvero un numero considerevole di pacchetti, e non una singola richiesta ad esempio per un DNS (sul considerevole sono presenti varie interpretazioni! non ci dilunghiamo però sulla questione che è un problema ancora aperto per tutti coloro che studiano IP), il TDP generi tag dello stesso tipo e, prima di inviare i pacchetti successivi nella rete, riaggiorni i TIB mediante il TDP.